Pandas is a powerful Python data analysis library that provides many built-in functions for working with data.
Some of the most commonly used Pandas functions are:
head():
Returns the first n rows of a DataFrame
#load the library
import pandas as pd
# read the daset from url
url="https://raw.githubusercontent.com/Opensourcefordatascience/Data-sets/master/blood_pressure.csv"
df = pd.read_csv(url)
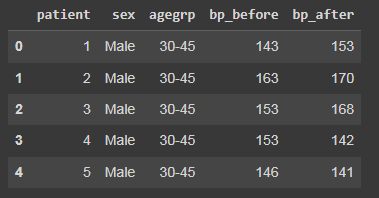
#check the first 5 rows
df.head()
The output:
tail():
Returns the last n rows of a DataFrame
df.tail()
The output:
info():
Prints information about a DataFrame, including the number of columns and rows, datatypes, and memory usage
df.info()
The output:
describe():
Calculates summary statistics for numeric columns in a DataFrame
df.describe()
The output:
value_counts():
Calculates the number of times each unique value occurs in a column
df['sex'].value_counts()
The output:
isnull():
Returns a Boolean Series indicating whether each element in a column is null
#check how many null values there are in each column
df.isnull().sum()
The output:
notnull():
Returns a Boolean Series indicating whether each element in a column is not null
#check how many not null values there are in each column
df.notnull().sum()
The output:
dropna():
Drops all rows, if any, that contain missing values
#modified the original dataset by deleting the rows with NA's
df.dropna(inplace = True)
The output: Not output, this modified the original dataset when inplace= True.